
Troubleshooting systems combine human knowledge and the computational power of computers, a fusion enabled by an underlying mathematical knowledge model capable of reasoning far better than humans.
Big data, Machine learning, and AI are buzzwords in the tech industry, and they are increasing in popularity. With good reason – systems like that are extremely useful for computer vision, speech recognition, and other pattern-identifying applications. Machine learning often builds on neural networks as they try to model the way the human brain works when we solve problems, and they are constructed as algorithms that can learn from and make predictions on data through interconnected groups of neurons simulated in software.
However, when it comes to troubleshooting, the brain is best compared to Bayesian Networks. In this article, we explain how Bayesian Networks can be used to actually “suggest actions to perform” in the most optimal sequence using probabilities, time, and cost and how observations of context and symptoms can dramatically affect the troubleshooting process. The goal is to dynamically guide the user through an optimized series of troubleshooting steps, ensuring that the user is always presented with the most optimal corrective step to perform at any given time in the context of the current troubleshooting scenario.
A sound model for troubleshooting
At the core of troubleshooting is not only the goal of arriving at the true diagnosis or conclusion of a given problem but also a desire to do so as efficiently as possible – the faster (or cheaper) we arrive at a conclusion the better. But, troubleshooting goes further than that because we want to establish a way to solve the problem while narrowing down the potential causes of the problem. As such, it is detection and problem solving mixed in the most optimal manner. Troubleshooting systems are often created as a combination of human expert knowledge and the computational power of modern computers – this fusion is enabled by an underlying mathematical model, and if the model is sound, the resulting system can potentially reason far better than any human.
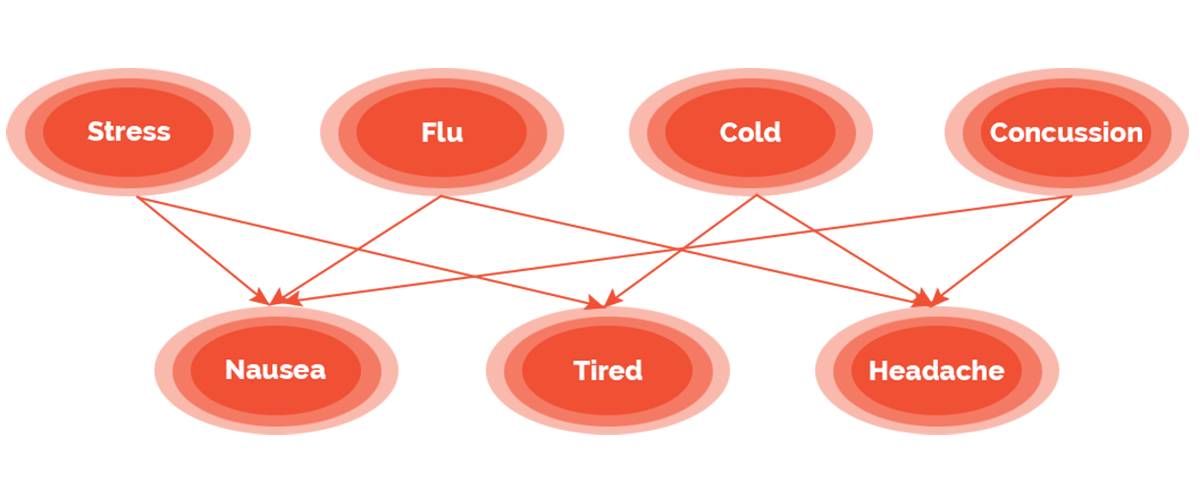
Bayesian networks
A Bayesian network is basically a probabilistic graph with a set of random variables and their conditional dependencies. Wikipedia has a very good description of Bayesian Networks and examples of how it can be used to tell the relationship between symptoms and diseases. Another example shows how “Grass Wet” can be related to “Sprinkler” and “Rain,” where we can see how Bayesian Networks can be used to answer interesting questions such as “What is the probability that the sprinkler is on, given that we see the grass is wet?”
The cool thing about using Bayesian Networks for decision making is the ability to reason under uncertainty and missing data or information, and it scales extremely well – where other decision and knowledge modeling technologies break down with scale and complexity, systems based on Bayesian Networks have no problems handling even the most complex problems.
Performing the right action at the right time
We have previously discussed the feasibility of structuring knowledge in causes and actions as that is a great way to model and share troubleshooting knowledge with other people.
However, we didn’t discuss how we make sure that the troubleshooting steps are presented to the user in the most efficient sequence – if we utilize only the probabilities of the causes, then we most likely solve the problem, but it might take us longer time and cost more money than absolutely necessary. If, instead, we expand on the concept and also consider the time that it takes to perform each action and the monetary cost associated, the sequence of steps will become much different as we are now ensuring that the most efficient step is always suggested.
The selection should be determined by the probability of the causes versus the cost of the actions. So, for instance, an action with a very high cost that solves a cause with a very high probability might not be suggested if there is another cause with a lower probability that is solved by an action with a very low cost. We need to calculate the most efficient way to resolve the issue by minimizing the overall cost of solving the problem – comparing cost versus probability for all elements in the troubleshooting knowledge model. This makes sure that troubleshooting becomes as efficient as possible.
Observations, Context, and Symptoms
Selecting the most efficient corrective action at the right time can be made even more efficient if we introduce observations. Capturing observations in software can be done using questions that are either answered manually by the user or automatically by the system using the Internet of Things. Observations greatly increase the confidence in identifying the underlying cause as the presence of various symptoms can help us select the best repair action to perform given the context.
If our car will not start, and we can observe that our dashboard doesn’t light up when we turn the ignition key – we change our perspective on battery and electrical causes. Consequently, we also adjust how efficient we believe it is to recharge the battery, replace it, or replace fuses and in which order to try out those repair actions.
Context
The context affects the causes of a troubleshooting model by inherent external properties, and it will affect how likely causes are in a certain situation. For example, it is because the operating system is Windows 8 that a certain printer driver defect cannot happen; it is not the printer driver defect that decides which OS to install on the computer.
Very often, a question models what happens to e.g., a piece of equipment over time or how the actual type of the equipment may influence the presence of certain causes. For example, if the equipment is more than two years old, a set of causes may become much more relevant. Or, if you are told that the user has Windows 8 installed, then a set of causes cannot happen.
Typical questions that help establish context for a troubleshooting scenario:
- How old is the truck?
- Less than one year old
- Between 1 and 3 years old;
- More than three years old.
- What operating system are you using?
- Windows 10
- Windows 8
- macOS Sierra
- Linux
Symptoms
A symptom is an effect created or induced by the causes. It is the presence of a certain cause (or set of causes) that directly affects the presence of the symptom and not the other way around. For example, a virus or bacterial infection can cause a person to get a fever; it is not the fever that leads to viral or bacterial infection.
Symptom questions are meant to reveal if something is broken, malfunctioning, or showing signs of abnormality, and symptom questions are characterized by always having exactly one answer that signifies that nothing is wrong.
Typical questions that indicate symptoms:
- Does the gearbox emit unusual sounds?
- Yes
- No
- What are the pressure readings from the engine oil system?
- Low (below 10 PSI)
- Normal (from 10 PSI to 30 PSI)
- High (above 30 PSI)
- What error code do you see on the display?
- E11-112
- E113 or E114
- E115-E222
- None
- Is the network of the TV box visible on the computer, and can the customer access the network of the TV box from the computer?
- No, the network is not visible
- Yes, the network is visible, but the customer cannot access the network
- Yes, the network is visible and can be accessed from the computer
Questions should also have time and cost associated, as it can take a long time to determine the context of a troubleshooting scenario, and it can take a long time to provide an answer regarding the presence of a symptom and this should be considered when determining the best troubleshooting sequence.
The examples below show how causes are listed with a probability and a question created with three answer possibilities. As we answer questions, we will change our point of view, and hence the probability of the causes will be updated. That, in turn, will change how efficiently we view the different actions we can take. The actions are displayed with the time it takes to perform them and the associated monetary cost.
A complete model for capturing and sharing troubleshooting knowledge
So, suppose we structure and organize our expert knowledge about error codes and problem areas in a knowledge model of causes, actions, and questions using probabilities, time, and cost. In that case, we can utilize sophisticated mathematical algorithms and Bayesian Networks to do the same reasoning a human expert does to find out what the most efficient way to resolve the issue at hand is – and even do it better than the experts. More importantly, we can provide this knowledge to the people who need it, when they need it and where they need it, and take context and symptoms into consideration.
About us
We have 25 years of experience in helping businesses of all sizes capturing, organize, and optimize expert knowledge. We work with clients in industries ranging from wind, mining, and electronics to consumer printing and telecommunications.
Get in touch and see why they trust Dezide to build brilliant knowledge bases powering the world’s best service organizations.